Part 1 of 3 : Why I stopped sending my personal files to OpenAI - and built a local AI benchmarking lab instead.
How a billing problem with a personal AI assistant led to a rigorous offline benchmarking study of four small language models - and the infrastructure battle I did not expect to fight.
The origin
I have been building a personal AI assistant that connects to my entire Google Workspace and Microsoft 365. One interface. Ask it anything about your schedule, your files, your contacts. No switching apps. No copy-pasting context.
The centrepiece of the personal AI assistant is a RAG pipeline - Retrieval-Augmented Generation. It lets me upload documents to a personal knowledge base and query them conversationally. Financial statements. Medical records. Work documents. Travel bookings. All of it searchable through a single assistant.
It worked beautifully. And it was quietly burning money.
“Every document I uploaded to test a feature, every query I ran while debugging - even the broken ones - was generating API calls to a paid embedding model. The meter ran whether the code worked or not.”
Every chunk of text processed, every semantic search during development, every iteration on retrieval quality - all of it hitting a commercial embedding API at cost-per-token. For production use serving real users, this is a justified expense. But during development, when you are uploading the same test files repeatedly and running dozens of queries to tune chunking strategies, it becomes an engineering tax on iteration speed.
Beyond cost, there was a development hygiene problem. Real files used for testing should not be travelling to external endpoints on every iteration. Local inference solves that cleanly without changing anything in production.
The question became obvious: could I run inference entirely locally? No API calls. No tokens leaving my machine. No bill for development work.
The model selection problem
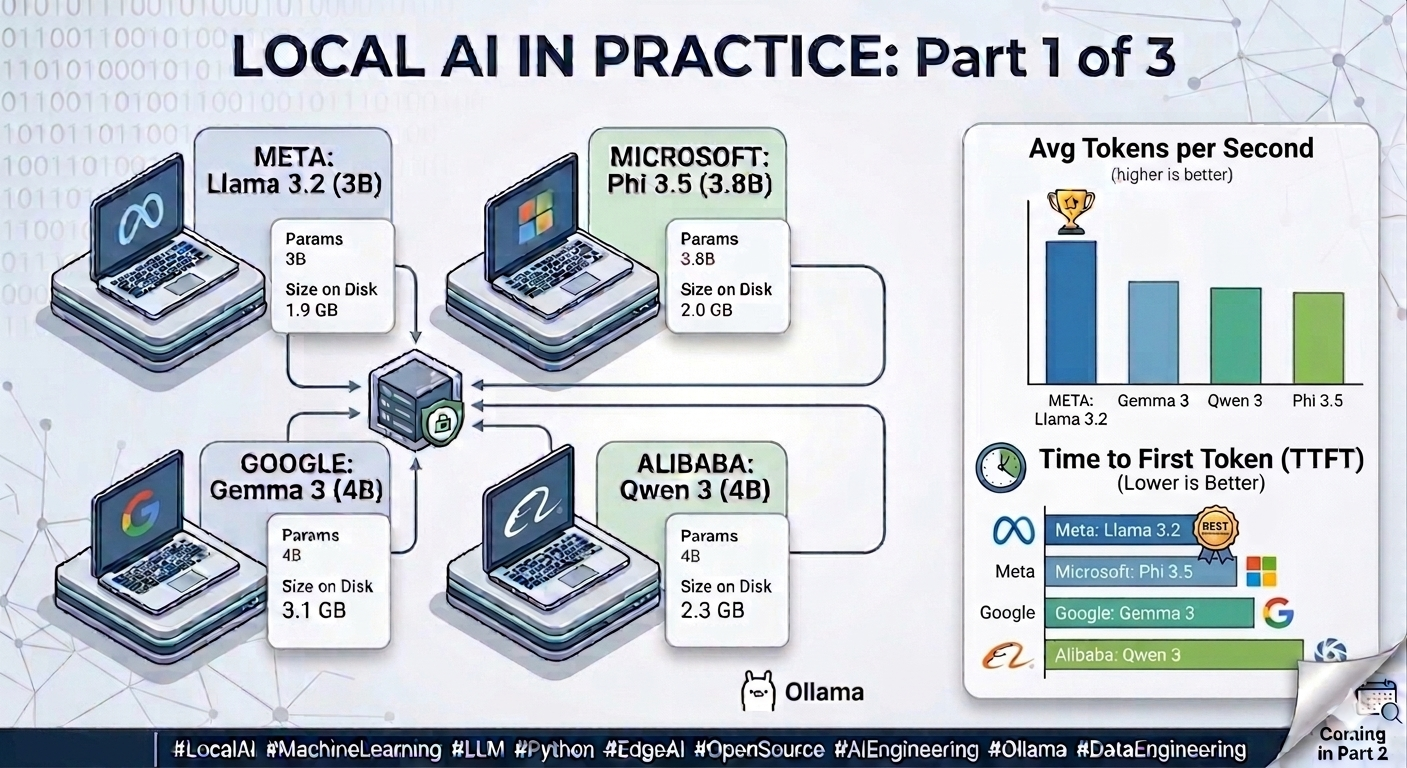
A quick search turned up dozens of Small Language Models in the 3B to 7B parameter range - compact enough to run on consumer hardware, capable enough to handle real tasks. Meta’s Llama. Microsoft’s Phi. Google’s Gemma. Alibaba’s Qwen. Each with different architectures, training philosophies, and benchmark claims.
I had seen this pattern before at work. When evaluating any technical component, you do not pick the one with the best marketing page. You define your requirements, build a test harness, and measure. Language models should be no different. That thinking became the foundation of my project local-model-lab.
The hardware reality check
The test machine is a Lenovo Yoga - a consumer laptop. Intel Arc GPU with 6.7GB available VRAM, 15.4GB system RAM. The kind of hardware a knowledge worker carries, a clinic deploys at a reception desk, or a field engineer takes on-site. Not an A100. Not a developer workstation. A realistic edge deployment device.
The first engineering detour was attempting to get GPU-accelerated
inference working. Intel Arc is not NVIDIA - there is no CUDA support,
no ROCm. The only viable path was Vulkan, an experimental backend that
Ollama supports but does not enable by default. After setting
OLLAMA_VULKAN=1 at the Windows User environment variable level,
killing stale tray processes, and verifying via ollama ps, the GPU
did engage - and delivered a meaningful speed improvement during initial
exploration runs.
But when the benchmarking framework moved into VS Code for systematic runs, the GPU acceleration did not carry over. The Ollama server process launched programmatically from Python consistently fell back to CPU. Solving this reliably would have required managing the full server lifecycle - killing and restarting with explicit environment flags before every session - introducing a fragile dependency that would be difficult to reproduce on another machine.
Finding #1 - CPU-only, by deliberate choice
The decision was made to standardise on CPU-only inference throughout the entire benchmark. Not because GPU acceleration is unimportant - the Vulkan exploration proved it delivers a real performance gain - but because a benchmark designed to represent edge deployment should reflect the hardware most edge devices actually have. Most consumer laptops do not have a discrete GPU. Most clinic terminals do not. Most field devices do not. CPU-only numbers tell a more honest and more reproducible story. Every result in this study reflects that baseline.
Model selection - four companies, one constraint
Not every model that looks right on paper works on constrained hardware. Mistral 7B runs, but slowly enough on CPU that a multi-hour benchmark becomes unreliable as thermal throttling sets in. Phi-4 and Llama 3.1 8B are simply too large - loading them on a consumer laptop works, but waiting minutes per response is not a realistic edge deployment scenario. Qwen3.5:4b was the closest call - right size, wrong behaviour. Its internal thinking mode consumed the entire token budget before producing a response, causing consistent timeouts.
After those eliminations, four models remained - compact enough for CPU inference, capable enough for meaningful evaluation, and representing a genuine cross-section of organisations, training philosophies, and architectural approaches. All capable of running at practical speeds on a standard consumer laptop with no GPU required.
What the speed numbers revealed
Before diving into the results, here is what each metric measures and why it matters for a real deployment:
| Metric | What it measures | Better when | Why it matters |
|---|---|---|---|
| Avg Tokens/s | How many tokens the model generates per second during active generation | Higher | Directly determines how fast a response streams to the user. A model at 13 T/s feels responsive. A model at 5 T/s feels sluggish. |
| TTFT (ms) | Time to First Token - how long from sending the request to receiving the very first word of the response | Lower | This is what the user experiences as “lag”. Even if a model generates quickly after starting, a 4-second wait before anything appears feels broken in an interactive application. |
| Latency (ms) | Total wall-clock time from request sent to response complete | Lower | The end-to-end experience. A function of both TTFT and tokens/s combined - a model can have good tokens/s but poor latency if TTFT is high, or vice versa. |
| Avg Tokens Generated | Average number of tokens in the model’s response across all prompts | Neither - context dependent | A proxy for verbosity. A model generating 350 tokens when 150 would suffice is not more helpful - it is less controlled. Higher token counts directly inflate latency on CPU inference. |
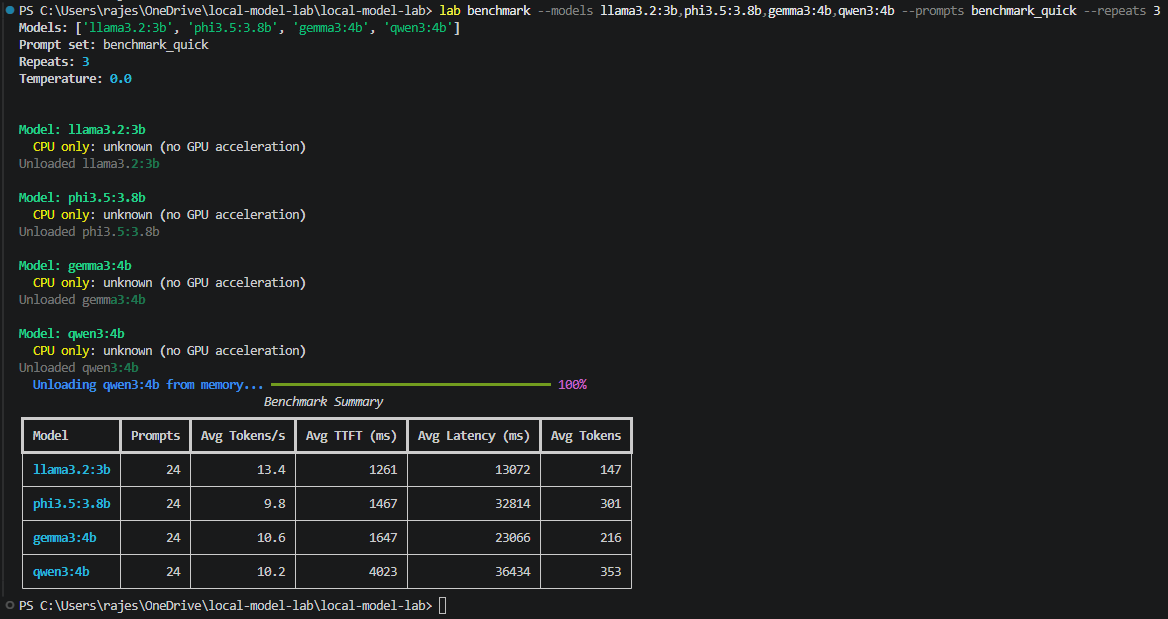
The benchmark harness was built from scratch using httpx talking directly to the Ollama REST API - no SDK wrapper. Direct HTTP control gives nanosecond-precision server-side timing. Each model ran 8 prompts across 6 categories, repeated 3 times at temperature 0.0. Warmup inferences were excluded. Models were explicitly unloaded between runs using keep_alive=0 - without this, two models resident simultaneously on constrained RAM degrades both.
| Model | Avg Tokens/s | TTFT (ms) | Latency (ms) | Avg Tokens Generated |
|---|---|---|---|---|
| 🏆 llama3.2:3b | 13.4 | 1,261 | 13,072 | 147 |
| gemma3:4b | 10.6 | 1,647 | 23,066 | 216 |
| qwen3:4b | 10.2 | 4,023 | 36,434 | 353 |
| phi3.5:3.8b | 9.8 | 1,467 | 32,814 | 301 |
Key findings:
Llama wins every speed metric - 40% faster token generation and 2.5x lower end-to-end latency than the slowest model, despite comparable parameter counts.
Qwen’s 4-second TTFT does not improve with warmup. It enters a thinking mode by default - generating internal chain-of-thought reasoning before responding. Powerful for hard problems. A UX dealbreaker for real-time applications where users expect immediate feedback.
Verbosity inflates latency independently of speed. Qwen generates 353 tokens on average - 2.4x more than Llama’s 147. A model that writes an essay when you asked for a sentence is not slower in the engineering sense - it is less controlled. Tokens-per-second and total latency must both be reported.
Temperature=0 is genuinely deterministic. Token counts were bitwise identical across completely independent runs. This confirms the measurement apparatus is working and establishes the reproducibility baseline needed before any variance analysis.
Thermal throttling is real and cloud benchmarks never show it. Under sustained CPU load, tokens/sec degraded 10–15% across all models. Edge hardware benchmarks must capture throttled performance, not peak performance.
Coming in Part 2: Coming in Part 2: Raw speed only tells you how fast a model can be wrong. Phase 2 tested something harder - whether these models can be trusted to return structured output reliably, every time, under varying conditions. The results changed the model selection entirely. Stay Tuned!