Part 2 of 3 - The models passed the speed test. Then I asked them for JSON.
Why the fastest model lost its lead the moment I needed structured output - and what I had to build to make any of them reliable.
Why speed is not enough
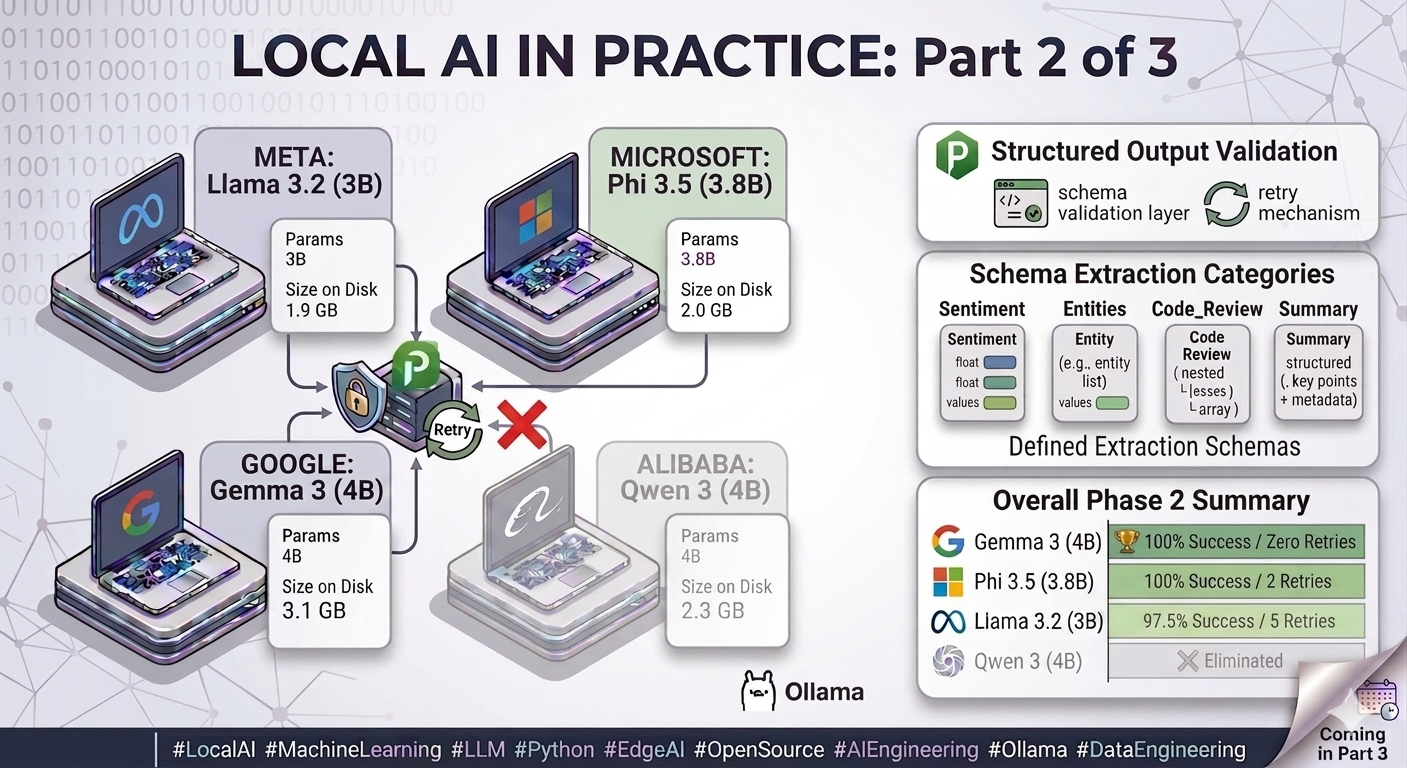
In Part 1 of this series, Llama 3.2:3b won every speed metric - 13.4 tokens per second, lowest latency, fewest tokens generated. On paper, an obvious choice.
But my personal AI assistant that motivated this entire project - does not just need fast responses. It needs to parse structured data from documents. Extract entities. Return results in a predictable, machine-readable format that downstream code can consume without defensive gymnastics.
“A model that generates fluent prose but cannot reliably return valid JSON is not a production component. It is a liability with a good demo.”
Phase 2 tested exactly that. And what came out the other side was less a performance table and more a list of engineering problems I had not anticipated going in.
What was built
To test this properly, I had to build a small enforcement layer around the models.
A JSON enforcement engine with four moving parts:
- A Pydantic v2 schema validation layer that checks every model response against a defined output structure
- A retry mechanism - if the model returns invalid JSON, it is reprompted once with the specific validation error included as feedback
- A structured extraction pipeline built to handle real model misbehaviour, not textbook cases
- A temperature sweep across 0.0, 0.3, 0.7, and 1.0 with 5 repeats per cell, to quantify how reliability degrades as stochasticity increases
Once the system was in place, I tested it against schemas of increasing structural complexity:
sentimententitiescode reviewsummaryFinding #2 - Schema validates. It does not instruct
Pydantic defines the expected output structure - field names, types, constraints. It is what catches a malformed response after the model has already generated it. The temptation is to paste the schema definition directly into the prompt and assume the model will infer what to return from it. Models in the 3–4B range cannot do that reliably. They see the notation but miss required fields, use wrong types, or produce structurally invalid output. Every field still has to be described in plain English in the prompt - “return a JSON object with a field called label containing either positive, negative, or neutral, and a field called confidence containing a float between 0 and 1.” Schema is the contract you enforce on the way out. The prompt is the instruction you give on the way in. They are not the same job.
Getting the enforcement layer right was one problem. What the models actually returned was another.
What only shows up when you actually run it
Getting the enforcement layer right was one problem. What the models actually returned was another.
These are not hypothetical scenarios. Each one surfaced during benchmark runs and had to be engineered around before the results meant anything.
Phi 3.5 outputs JavaScript-style inline comments inside JSON.
Responses like {"label": "positive" // sentiment} are not valid JSON - json.loads() throws immediately.
The obvious fix is a regex that strips //.* before parsing.
That works until a URL appears inside a string value: {"source": "https://example.com"}. The // matches, everything after it gets stripped, and you get {"source": "https:"} - technically valid JSON, no exception raised, wrong data written downstream without complaint.
The fix has to know whether the // it encounters is inside a string literal or outside one. Outside - strip it. Inside - leave it alone. That requires tracking quote boundaries, which means also handling escaped quotes \".
At the same time, the extractor needs to correctly identify where a nested JSON object starts and ends - not stop at the first } it sees inside a nested field. That requires a brace-depth counter: increment on {, decrement on }, close when the counter hits zero.
Each fix sounds simple in isolation. The problem is each one breaks on the next edge case. The correct implementation handles comment-stripping, string boundaries, and brace-depth together in a single pass - and the only way you find that out is by running it against real model output.
Qwen’s thinking mode exhausts the generation limit before the response closes.
By default, Qwen 3 generates an internal chain-of-thought block before writing its actual answer - reasoning through the problem before committing to output. On local inference via Ollama, you set a num_predict cap to keep generation time bounded on constrained hardware. This benchmark used 1,200 tokens - enough for every other model to complete the most complex schema comfortably, with headroom to spare.
Qwen’s internal reasoning consumed most of that allocation before the JSON response even started, leaving the output truncated - closing braces missing, fields incomplete - and Pydantic validation failing consistently.
The obvious counter is to simply raise the limit. The problem is that doing so for one model breaks the comparison - the other three completed identical tasks well within budget. A model that needs 3x the token allocation to match what its competitors produce within constraints is not slower by a measurable amount. It is a different class of tool for this use case.
The /no_think prompt directive is supposed to suppress the chain-of-thought behaviour, but proved unreliable when followed by other instructions. The think: False Ollama API parameter is the correct fix - but even with thinking fully suppressed, Qwen’s verbose generation pattern persisted. On CPU inference, where response time scales directly with tokens generated, that verbosity alone makes it unsuitable for bounded extraction tasks on this hardware.
It was eliminated here - not because the limit could not be raised, but because raising it would mean measuring a different thing.
Non-greedy regex destroys nested JSON.
When a model response is not pure JSON - preamble text followed by the object - you need to extract the JSON portion before parsing it. The pattern r"\{.*?\}" looks like a reasonable starting point: find the first {, match until the first }. The problem is “first }.” On a nested object, that is the brace closing an inner field, not the outer object. What the extractor returns is a truncated fragment. Sometimes that fragment fails json.loads() and you catch it. More dangerous is when it succeeds - a partial object that is technically valid JSON, missing fields, no exception raised, wrong data written downstream without any signal that something went wrong.
The correct implementation reads the response character by character, maintaining a depth counter - increment on {, decrement on }, stop when the counter returns to zero. That correctly spans the full object regardless of nesting depth. The counter also has to ignore { and } characters inside string values, which means tracking quote boundaries and handling escaped quotes \". The same string-awareness required for the Phi comment-stripping problem appears here too - these are not independent fixes.
The temperature variance results
Temperature controls how deterministic a model’s output is. At 0.0, the model always picks the highest-probability next token - the same prompt produces the same output every time. As temperature rises, randomness increases. For structured output, that randomness is a risk - the same prompt that returns valid JSON at 0.0 might return something malformed at 0.7.

The question this phase was testing: how much does reliability degrade as stochasticity increases?
Five repeats per temperature per schema, three models (Qwen eliminated before this phase):
| Temperature | Description |
|---|---|
| 0.0 | Deterministic baseline |
| 0.3 | Light variance |
| 0.7 | Moderate stochasticity |
| 1.0 | High variance |
Success rate by temperature:
| Temperature | gemma3:4b | llama3.2:3b | phi3.5:3.8b |
|---|---|---|---|
| 0.0 | 100% | 100% | 100% |
| 0.3 | 100% | 100% | 100% |
| 0.7 | 100% | 90% | 100% |
| 1.0 | 100% | 100% | 100% |
↻ = retry was needed. Temperature 0.0 produced the highest structured output reliability across all models.
Two things stand out. Gemma and Phi held 100% across all four temperatures - reliability did not degrade as variance increased. Llama dropped at 0.7 but recovered at 1.0, which suggests the failure was not purely stochasticity-driven. The nested enum structure of the code_review schema was the more likely factor - at moderate randomness, Llama occasionally produced output that was structurally valid JSON but did not satisfy the schema constraints. A single retry did not always recover it.
Temperature 0.0 is the safest baseline for structured extraction tasks. But the more important finding is that schema complexity mattered more than temperature level.
Structured output success rates
The schema table shows where retries were needed. The summary table shows the overall picture per model. A retry means the model’s first response failed Pydantic validation - it was reprompted once with the specific error included as feedback.
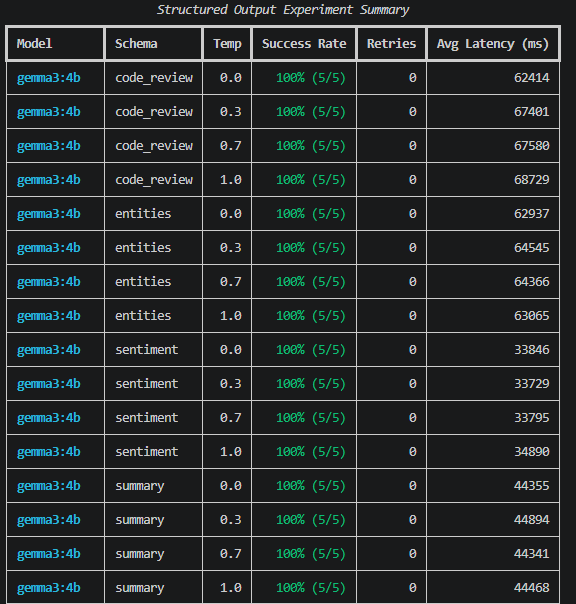
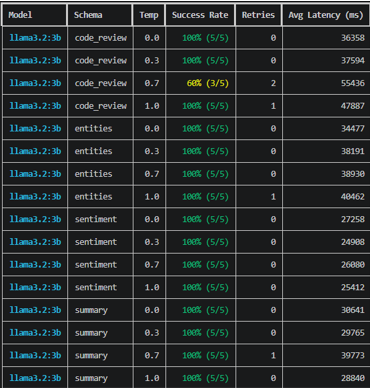
Success rate by model and schema:
| Schema | gemma3:4b | llama3.2:3b | phi3.5:3.8b |
|---|---|---|---|
| sentiment | 100% | 100% | 100% |
| entities | 100% | 100% (1↻) | 100% |
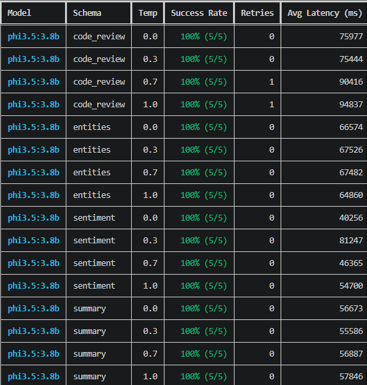
| code_review | 100% | 90% (3↻) | 100% (2↻) |
| summary | 100% | 100% (1↻) | 100% |
*↻ = retry was needed.
| Model | Overall Success Rate | Retries Needed | Status |
|---|---|---|---|
| 🏆 gemma3:4b | 100% | Zero | All schemas · All temperatures |
| phi3.5:3.8b | 100% | 2 total (code_review only) | All schemas · Well-understood quirk |
| llama3.2:3b | 97.5% | 5 total (3 on code_review, 1 on entities, 1 on summary) | Drops at temperature 0.7 |
| ❌ qwen3:4b | Eliminated | N/A | Token budget exhausted before JSON closes |
Key findings:
Gemma 3:4b went 100% across every schema at every temperature with zero retries. For any pipeline where structured output must be machine-readable on every call - my personal AI assistant’s retrieval step being the direct example - that reliability profile is the only number that matters.
Phi 3.5:3.8b also hit 100%, with two single retries on the code_review schema. The inline comment issue is real, but once handled in the extraction layer, Phi produces consistent structured output. A known quirk is an engineerable quirk.
Llama 3.2:3b dropped to 60% on code_review at temperature 0.7. The nested enum structure in that schema is the most demanding - at higher stochasticity, Llama occasionally generates structurally valid but schema-non-compliant output that a single retry did not recover. The 2.5% overall failure rate looks small. Concentrated in the hardest schema under the highest variance, it is not.
Qwen 3:4b was eliminated. Its thinking mode exhausts the
num_predictgeneration limit before consistently closing complex JSON objects. Not a bug - an architectural characteristic. But one that makes it unsuitable for bounded structured extraction tasks on constrained hardware.
Finding #3 - Model selection is not a single decision
The Phase 1 and Phase 2 results do not agree with each other - and that is the most actionable finding so far. Llama wins on speed. Gemma wins on structured output reliability. Phi sits in the middle: fast enough, reliable enough, with one well-understood quirk to engineer around. Different components of the same pipeline may warrant different models, chosen for different properties. That is not a problem. That is an architecture decision.
For my personal AI assistant specifically, the RAG pipeline’s retrieval step needs to return structured results on every call - chunk text, similarity score, source filename, metadata. A 2.5% failure rate on that step is not a statistics problem. It is a user experience problem. Gemma’s reliability profile makes it the candidate for structured extraction. Llama’s speed advantage makes it the candidate for conversational and summarisation tasks. The benchmark is starting to answer real questions.
Coming in Part 3: Raw speed tells you how fast a model can be wrong. Structured output tells you whether it can be trusted. Part 3 tests whether any of them are actually good. Stay tuned.