Part 3 of 3 - Fast. Reliable. But are they actually good?
Three models. Same hardware. Same constraints. All fast. All reliable. But when it actually matters - which one produces the best output?
The context
In Part 1, I benchmarked four Small Language Models (SLM) on raw inference speed on CPU-only constrained hardware. Llama 3.2:3b won every speed metric. In Part 2, I tested structured JSON output reliability across four schemas and four temperature settings. Gemma 3:4b delivered 100% success with zero retries - Qwen was eliminated on token budget grounds.
Three models entered Phase 3. One question remained: across a broad, representative set of real tasks, which model actually produces the best output?
Methodology - scoring without an LLM judge
Most model evaluation frameworks use an LLM-as-judge - a larger model that scores the outputs of the smaller ones. That is not an option here. The system is entirely offline. Routing outputs to a cloud API to evaluate a local benchmark would defeat the entire purpose of the project.
The scoring system is deterministic and fully offline - four dimensions on a 0 to 5 scale, 20 points maximum:
| Dimension | How it is measured |
|---|---|
| Relevance (0–5) | Proportion of expected domain keywords present in the response |
| Completeness (0–5) | Response length vs minimum expected length; structural depth for multi-step tasks |
| Format Compliance (0–5) | JSON validity for structured prompts; code fences for code prompts |
| Coherence (0–5) | No repetition loops, no refusals, no mid-sentence truncation |
40 prompts across 7 categories:
I evaluated models across 4 dimensions (relevance, completeness, format, coherence) using 40 prompts across 7 categories.
- Factual Recall
- Reasoning
- Summarisation
- Code Generation
- Creative Writing
- Multi-step Instructions
- Structured Output
Each prompt run 3 times per model. 360 total inferences. Temperature fixed at 0.0 - variance effects were already characterised in Phase 2.
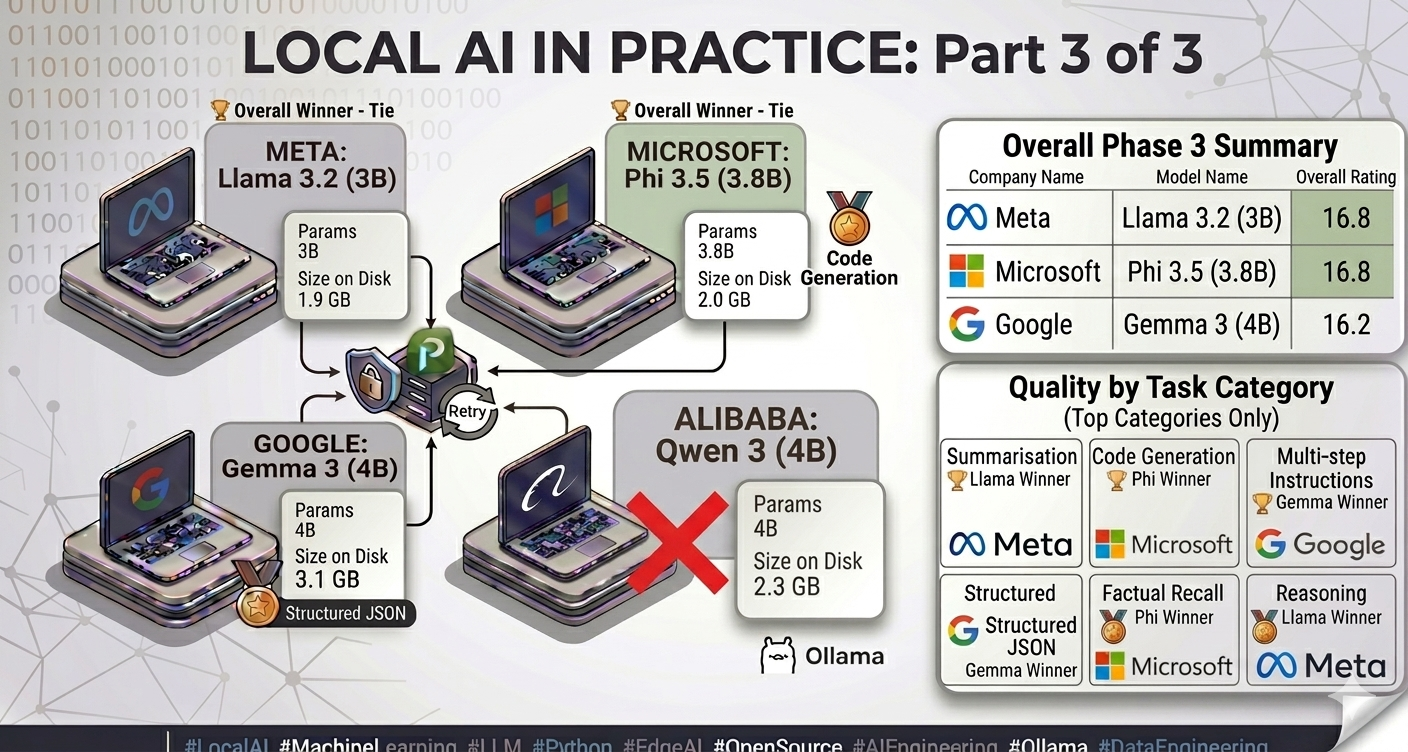
The overall results
| Model | Avg T/s | TTFT (ms) | Latency (ms) | Quality / 20 | Timeouts |
|---|---|---|---|---|---|
| 🏆 llama3.2:3b | 13.1 | 6,467 | 26,638 | 16.8 | 0 |
| 🏆 phi3.5:3.8b | 10.4 | 5,739 | 37,428 | 16.8 | 0 |
| gemma3:4b | 10.4 | 7,156 | 37,640 | 16.2 | 0 |
The headline number - Llama and Phi tied at 16.8/20, Gemma at 16.2/20 - understates how different the results are by category. The averages converge precisely because each model has distinct strengths in different task types. Choosing based on overall score alone would be the wrong conclusion.
Quality by category
| Category | gemma3:4b | llama3.2:3b | phi3.5:3.8b |
|---|---|---|---|
| Factual Recall | 16.5 | 16.3 | 16.0 |
| Reasoning | 17.2 | 17.5 | 17.3 |
| Summarisation | 16.2 | 17.8 | 17.2 |
| Code Generation | 16.5 | 16.2 | 18.0 |
| Creative Writing | 15.5 | 15.8 | 16.0 |
| Multi-step Instructions | 15.3 | 16.5 | 16.0 |
| Structured Output | 16.3 | 17.1 | 16.6 |
Where each model wins
Summarisation → Llama (17.8/20)
Concise, focused, structured. Llama consistently produces summaries that hit the key points without padding. This is the task type most directly relevant to my personal AI assistant’s document knowledge base - and it is where Llama’s lower verbosity becomes an asset rather than a limitation. A model that writes less is not worse at summarisation. It is more controlled.
Code generation → Phi (18.0/20)
The highest single-category score across the entire study. Microsoft’s training philosophy - high-quality synthetic data over raw corpus scale - pays visible dividends here. Phi produces cleaner, more correct code with better fence formatting than either competitor. For any deployment where code generation is a primary task, Phi is the clear choice.
Reasoning → effectively tied
All three models scored within 0.3 points of each other across reasoning prompts. At 3–4B parameters, reasoning capability has largely converged across training approaches and organisations. The differences that exist are within measurement noise at this scale.
Structured JSON reliability → Gemma (confirmed from Phase 2)
Phase 3 reinforced Phase 2’s finding. Gemma’s format compliance score is the most consistent across all schema types. When the output must be machine-readable every time, Gemma’s determinism is the differentiating property.
Quality dimension breakdown
| Dimension | gemma3:4b | llama3.2:3b | phi3.5:3.8b |
|---|---|---|---|
| Relevance | 3.9 | 4.0 | 4.1 |
| Completeness | 5.0 | 5.0 | 5.0 |
| Format Compliance | 4.0 | 4.0 | 4.0 |
| Coherence | 3.4 | 3.8 | 3.6 |
Coherence is where the gap is largest. Llama scored 3.8/5 against Gemma’s 3.4/5. Gemma showed occasional repetition in longer responses - sentences restating the same point with slight rewording. Not a failure mode. A characteristic. One that matters for user experience on longer-form generation tasks, and a known side effect of training on heavily filtered corpora.
Finding #4 - No single model wins everything
Three phases. 360 inferences. The conclusion is the same one that kept surfacing in Phase 1 and Phase 2: no model dominates across all dimensions. Llama is fastest and best at summarisation. Phi wins code generation by a clear margin. Gemma is the most reliable for structured output. The overall quality scores converge - but the category-level data shows exactly why that average is misleading. A system designed around a single “best” model would be making the wrong trade-offs for at least some of its components.
Final recommendations by use case
| Use case | Recommended model | Reason |
|---|---|---|
| Latency-sensitive / real-time assistant | llama3.2:3b | Fastest at 13.1 T/s, best overall quality |
| Code generation and review | phi3.5:3.8b | Highest code quality score (18.0/20) |
| Structured JSON pipelines | gemma3:4b | 100% reliability, zero retries |
| Document summarisation | llama3.2:3b | Highest summarisation score (17.8/20) |
| Memory-constrained deployment | phi3.5:3.8b | Smallest memory footprint |
| General quality + speed balance | llama3.2:3b | Best all-round across speed and quality |
A note on model size and speed: Llama 3.2:3b’s performance advantage is not accidental - it is the smallest model in the study at 1.9GB and 3B parameters. Fewer parameters means less computation per token. A smaller memory footprint means less RAM pressure on CPU inference. But size alone does not determine quality - Phi 3.5:3.8b matches Llama’s overall quality score despite being larger, and outperforms it significantly on code generation. The right conclusion is not “smaller is better” - it is “smaller is faster, but training quality determines what you get for that speed.”
Back to where this started - what it means for my Personal AI Assistant
The problem that triggered this entire project was practical: API embedding costs and data privacy during development of a personal AI assistant. Three phases and 360 inferences later, the answer is more nuanced than I expected when I started.
For my Personal AI Assistant’s conversational and summarisation components - local inference with Llama 3.2:3b is viable. Fast enough, coherent enough, zero ongoing cost. For structured extraction from documents - Gemma is the right component, chosen specifically for its JSON reliability profile, not its overall benchmark score. For any future code-aware features - Phi is the candidate.
“Model selection is not a single decision across an entire system. It is a series of component-level decisions, each driven by the specific performance property that matters most for that component.”
The broader significance extends beyond a personal project. The same constraints that motivated this work - data that cannot leave the building, inference cost at scale, offline environments - are blocking AI adoption in regulated industries today. Healthcare providers cannot send clinical notes to commercial APIs. Law firms processing privileged documents have the same restriction. Defence and financial services operate under stricter constraints still.
The 3–4B parameter models from Meta, Microsoft, and Google now run at production-viable speeds on consumer hardware. The capability is here. The engineering work - understanding which model to choose, on what hardware, verified under what conditions, for which specific task - is what makes that capability real and deployable. The models are ready. The constraint is no longer capability - it’s engineering decisions.
Full source and data
The complete benchmark dataset, prompt suite, scoring methodology, raw JSONL results, and generated comparison report are published and fully reproducible.
GitHub: github.com/rajeshkancharla/local-model-lab
Stack: Python 3.13 · httpx · Pydantic v2 · FastAPI · Typer · Rich · psutil · pytest · Ollama v0.20.0
This is Part 3 of a 3-part series. Part 1 covered infrastructure setup and inference speed benchmarking. Part 2 covered structured output reliability and temperature variance.